Crédits : Ce cours est presque intégralement repris du cours proposé par Gilles Lassus sur le Codage des caractères, diffusé sous licence CC BY-SA
Comme nous l'avons déjà vu, une machine ne comprend que le langage binaire. Ainsi, même les textes, et donc les caractères doivent être représentés par des mots de 0 et de 1. Nous allons voir comment dans ce document !
Avant 1960, il existait de nombreux systèmes pour coder les caractères, souvent incompatibles entre eux.
En 1960, l'organisation internationale de normalisation (ISO) décide de créer la norme ASCII (pour American Standard Code for Information Interchange) pour uniformiser le codage des caractères.

Fig. 1 - Table ASCII.
Crédit : ASCII-Table.svg: ZZT32derivative work: Usha, Public domain, via Wikimedia Commons
En ASCII, 127 « points de code » (= nombres associés aux caractères) sont disponibles. Les caractères sont donc codés sur 7 bits.
Par exemple, le caractère A correspond à la valeur décimale 65 ou à la valeur hexadécimale 41. Ainsi, il est représenté en binaire sur 7 bits par 1000001.
>>> bin(65) # conversion en binaire
'0b1000001'La fonction chr renvoie le caractère correspondant à la valeur décimale passée en paramètre :
>>> chr(78)
'N'
>>> chr(123)
'{'Si on dispose de la valeur binaire d'un caractère codé en ASCII, on peut trouver ce caractère facilement en utilisant int puis chr :
>>> int('1100101', 2) # conversion en décimal
101
>>> chr(101)
'e'Ou directement :
>>> chr(int('1100101', 2))
'e'🐍 Question 1 : Utilisez les fonctions int, chr pour déterminer le caractère codé 1010101 en ASCII.
🐍✍️ Question 2 : En vous aidant de la fonction bin vérifiez la cohérence avec la table ASCII donnée au-dessus. Expliquez.
On dispose d'un message msg écrit en ASCII et on souhaite décoder ce message.
1101100 1100101 1110011 100000 1001110 1010011 1001001 100000 1100011 100111 1100101 1110011 1110100 100000 1101100 1100101 1110011 100000 1101101 1100101 1101001 1101100 1101100 1100101 1110101 1110010 1110011
Comme ce serait long de le faire à la main caractère par caractère, on va écrire un programme qui permet de le faire.
Mais avant cela, une présentation de la méthode split qui s'applique à une chaîne de caractères et qui sera utile pour la suite.
La méthode split permet de décomposer une chaîne de caractères en une liste en utilisant le caractère séparateur passé en paramètre :
>>> ch1 = "une phrase d'exemple"
>>> ch1.split('e')
['un', ' phras', " d'", 'x', 'mpl', '']
>>> ch2 = "pou, caillou, genou, chou, hibou, joujou, bijou"
>>> ch2.split(',')
['pou', ' caillou', ' genou', ' chou', ' hibou', ' joujou', ' bijou']
>>> ch2.split(', ') # observez bien la différence avec l'instruction prédécente
['pou', 'caillou', 'genou', 'chou', 'hibou', 'joujou', 'bijou']
🐍 Question : Complétez le code ci-dessous qui permet de décoder notre message.
L'idée est de convertir le message binaire en une liste de codes binaires puis de parcourir les différents codes binaires de cette liste pour les convertir en caractères et construire la chaîne de caractères qui décode ce message.
msg = "1101100 1100101 1110011 100000 1001110 1010011 1001001 100000 1100011 100111 1100101 1110011 1110100 100000 1101100 1100101 1110011 100000 1101101 1100101 1101001 1101100 1101100 1100101 1110101 1110010 1110011"
liste_codes_ascii = msg.split(...)
msg_decode = ""
for code in ...:
caractere = ...
msg_decode = msg_decode + caractere
print(msg_decode)La norme ASCII convient bien à la langue anglaise, mais lorsque d'autres personnes que des américains ou des anglais ont voulu s'échanger des données textuelles, certains caractères étaient manquants : é, è, à, ñ, Ø, Ö, β, 漢, ...
Les 7 bits de la table ASCII étaient insuffisants pour ajouter ces nouveaux caractères, il a donc été décidé de coder les caractères sur 8 bits pour arriver à ... 256 caractères.
C'est ainsi que de nouvelles tables, codant les caractères sur 8 bits, virent le jour.
En 1986, la table ISO 8859-1, aussi appelée Latin-1, a vu le jour et était principalement utilisée en Europe car elle ajoutait aux caractères de la table ASCII les caractères de l'alphabet du "latin".
Mais il manquait encore des caractères et après de nombreuses modifications successives (la dernière en date rajoutant par exemple le symbole €), on a aboutit à la célèbre table ISO 8859-15, appelée aussi Latin-9 :
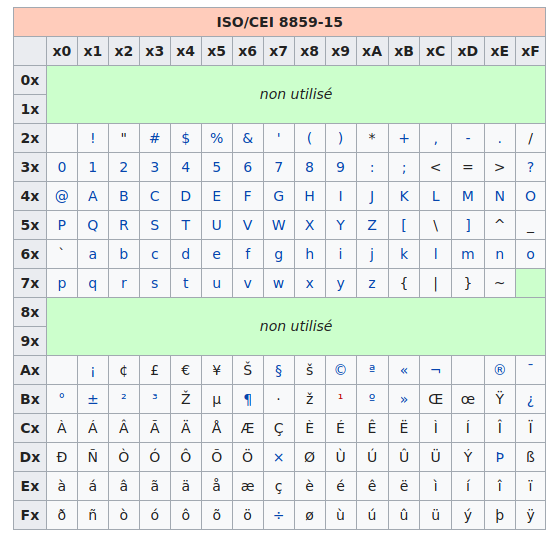
Fig. 2 - Table ISO/CEI 8859-15.
Source : article ISO/CEI 8859-15 sur Wikipédia.
Les codes sont donnés en hexadécimal :
Ax et de la colonne x4), donc au nombre décimal 164.65... comme en ASCII ! Oui, la (seule) bonne idée aura été d'inclure les caractères ASCII avec leur même code, ce qui rendait cette nouvelle norme rétro-compatible.
Rétro-compatibilité avec l'ASCII
Si vous regardez les 128 premiers caractères de cette table, de
00à7Fen hexadécimal (soit de 0 à 127 en décimal), on retrouve exactement les caractères de la table ASCII. Cela permet à la table ISO 8859-15 d'être compatible avec la table ASCII et ainsi pouvoir décoder sans erreur des textes encodés préalablement avec la table ASCII.
Exemple :
Le fichier test.txt contient le texte Ça marche très bien ! enregistré avec l'encodage Latin-9. Ce fichier est ensuite ouvert avec un éditeur hexadécimal, qui permet d'observer la valeur des octets qui composent le fichier. (Comme le fichier est un .txt, il ne contient que les données et rien d'autre.)
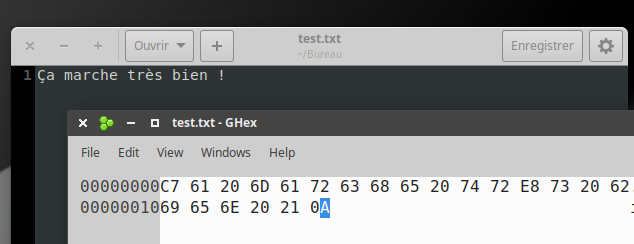
Fig. 3 - Ouverture d'un fichier avec un éditeur hexadécimal.
Parfait, mais comment font les Grecs pour écrire leur alphabet ? Pas de problème, il leur suffit d'utiliser... une autre table, appelée ISO-8859-7 :
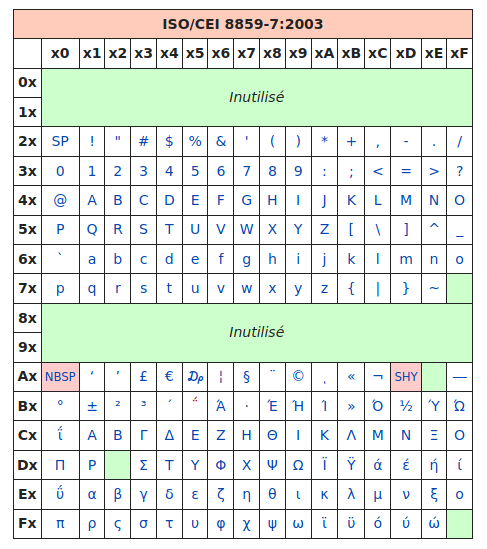
Fig. 4 - Table ISO/CEI 8859-7.
Source : article ISO/CEI 8859-7 sur Wikipédia.
On retrouve les caractères universels hérités de l'ASCII, puis des caractères spécifiques à la langue grecque... oui mais les Thaïlandais alors ?
Pas de problème, ils ont la ISO-8859-11 :
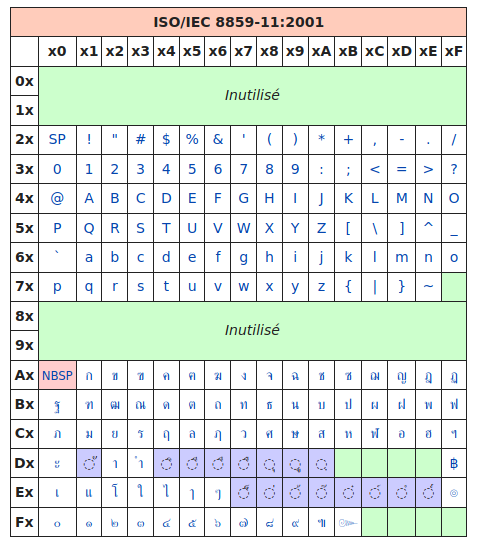
Fig. 5 - Table ISO/CEI 8859-11.
Source : article ISO/CEI 8859-11 sur Wikipédia.
Évidemment, quand tous ces gens veulent discuter entre eux, les problèmes d'encodage surviennent immédiatement : certains caractères sont remplacés par d'autres.
Il essaie de deviner l'encodage utilisé... Parfois cela marche, parfois non.
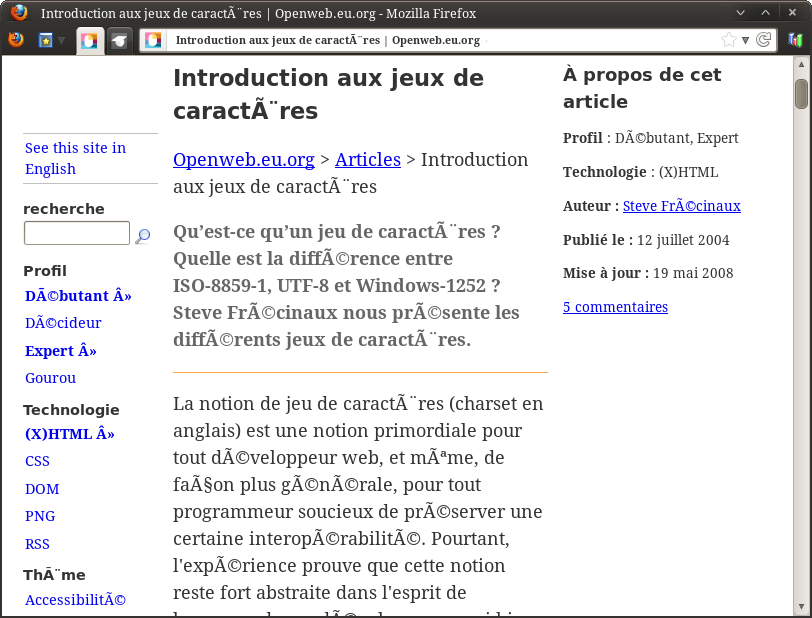
Fig. 6 - Problème d'affichage dans un navigateur.
L'exercice 5 permettra d'expliquer ce genre d'affichages étranges. Mais il faut d'abord aborder l'encodage UTF-8, le plus utilisé actuellement (et de loin).
Normalement, pour un navigateur, une page web correctement codée doit contenir dans une balise meta le charset utilisé (charset signifie "jeu de caractères"), comme sur la ligne 4 ci-dessous :
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
</body>
</html>Mais parfois, il n'y a pas d'autre choix pour le logiciel d'essayer de deviner l'encodage qui semble être utilisé.
On a ouvert un fichier texte avec un éditeur hexadécimal comme le montre la capture d'écran ci-dessous.
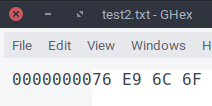
✍️ Question : Le mot représenté par les octets ci-dessous est-il encodé en ASCII ou en Latin-9 ? Quel est ce mot ? Expliquez.

En 1996, le Consortium Unicode décide de normaliser tout cela et de créer un système unique qui contiendra l'intégralité des caractères dont les êtres humains ont besoin pour communiquer entre eux.
Slogan du Consortiom Unicode
Unicode provides a unique number for every character,
no matter what the platform,
no matter what the program,
no matter what the language.
✍️ Question : Donnez la traduction de ce slogan.
Le consortium crée l'Universal character set Transformation Format : l'UTF. Ou plutôt ils en créent... plusieurs 😭 :
Pourquoi est-ce encore si compliqué ?
En UTF-32, 32 bits sont disponibles, soit $2^{32}=4294967296$ caractères différents encodables. C'est largement suffisant, mais c'est surtout très très lourd !
D'autres encodages plus légers, mais plus complexes, sont donc proposés, arrêtons-nous sur l'UTF-8 qui est de loin le plus utilisé.
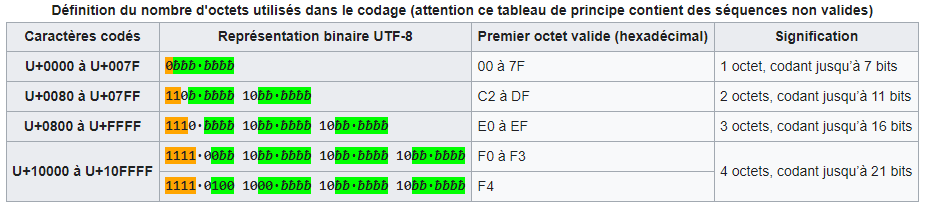
Fig. 7 - Codage des caractères en UTF-8.
Source : article UTF-8 de Wikipedia.
Le principe fondateur de l'UTF-8 est qu'il est adaptatif : les caracères les plus fréquents sont codés sur un octet, qui est la taille minimale (et qui donne le 8 de "UTF-8"). Les autres caractères peuvent être codés sur 2, 3 ou 4 octets au maximum.
Rétro-compatibilité avec l'ASCII
Les caractères de
0000à007Fen hexadécimal sont représentés sur 1 octet (codant 7 bits) et correspondent aux caractères de la table ASCII, ce qui assure la rétro-compatibilité comme évoquée plus haut. C'est la première ligne du tableau ci-dessus.
U+20AC.U+20AC :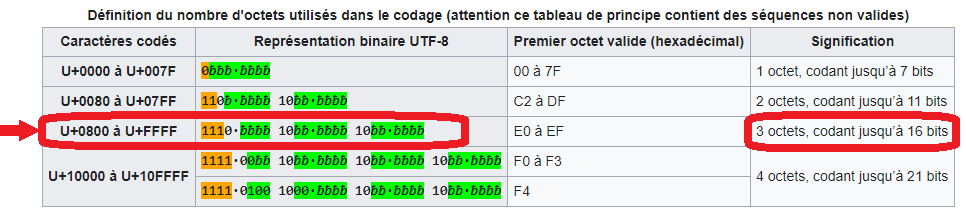
U+20AC correspond à la troisième ligne car en hexadécimal 20AC est compris entre 0800 et FFFF : il faudra donc 3 octets pour coder le symbole « € » en UTF-8.>>> int('20AC', 16) # conversion d'hexadécimal (base 16) en décimal (base 10)
8364
>>> bin(8364) # conversion en binaire (base 2)
'0b10000010101100'10000010101100 en binaire, soit sur 14 bits. Il faudra donc rajouter deux zéros à gauche pour arriver à 16 bits : 00100000101011000010, puis 000010 et enfin 101100) et on obtient alors :11100010 10000010 10101100
11100010 10000010 10101100 en UTF-8.La fonction ord de Python permet de connaître la valeur décimale en UTF-8 d'un caractère :
>>> ord("€") # renvoie 8364 comme vu plus haut
8364🐍 Question 1 : Utilisez les fonctions ord puis bin pour écrire en binaire le nombre associé au caractère é en UTF-8.
✍️ Question 2 : En vous aidant de l'exemple de l'encodage du caractère « € » en UTF-8, déterminez l'encodage du caractère é en UTF-8. Détaillez la démarche.
🐍 Question 3 : Convertissez les deux octets obtenus (grâce à int) puis en hexadécimal (grâce à hex).
✍️ Question 4 : Si un logiciel considère à tort que les deux octets servant à encoder le é en UTF-8 servent à encoder deux caractères en ISO 8859-15, quels seront ces deux caractères ? Expliquez.
✍️ Question 5 (bilan) : Expliquez en quelques lignes, pourquoi certains caractères s'affichent parfois de façon étrange lorsque que l'on ouvre certains documents comme on le voit dans la capture d'écran du paragraphe "Que fait un logiciel à l'ouverture d'un fichier texte ?".
Désormais, la majorité des sites Web utilisent maintenant l'UTF-8, tout comme les systèmes d'exploitation récents.
De 2001 à 2010 :

Fig. 8 - Évolution de l'utilisation de l'UTF-8 sur le Web entre 2001 et 2010.
Crédit : Krauss, CC BY-SA 4.0, via Wikimedia Commons
De 2012 à 2022 :
Fig. 9 - Évolution de l'utilisation de l'UTF-8 sur le Web entre 2012 et 2022.
Source : https://w3techs.com/technologies/history_overview/character_encoding/ms/y.
Grâce à la fonction open on peut définir l'encodage utilisé pour lire ou écrire dans un fichier avec Python.
Le fichier texte mon_fichier_utf8.txt encodé en UTF-8 contient la phrase :
Ce pull est très cher, il coûte 100 €.On va l'ouvrir pour en lire le contenu avec Python.
Si on l'ouvre en définissant le bon encodage, grâce au paramètre encoding, il n'y a aucun problème.
>>> f = open('fichier_utf8.txt', 'r', encoding='utf-8') # 'r' pour read (lecture)
>>> contenu = f.read() # lecture
>>> f.close() # fermeture du flux de lecture>>> print(contenu)
Ce pull est très cher, il coûte 100 €.En revanche, si on le lit avec le mauvais encodage, par exemple Latin-9, on obtient les problèmes évoqués plus haut :
>>> f = open('fichier_utf8.txt', 'r', encoding='latin9') # MAUVAIS ENCODAGE
>>> contenu = f.read() # lecture
>>> f.close() # fermeture du flux de lecture>>> print(contenu)
Ce pull est trÚs cher, il coûte 100 â¬Lorsqu'on veut écrire dans un fichier, on peut aussi définir l'encodage que l'on utilisera (toujours grâce au paramètre encoding). Par exemple, ici on ouvre un fichier fichier_latin9.txt (le fichier est créé car n'existe pas) en mode écriture en utilisant la table Latin-9 :
>>> f2 = open('fichier_latin9.txt', 'w', encoding='latin9') # 'w' pour write (écriture)
>>> f2.write("Représentation d'un texte en machine") # écriture
>>> f2.close()Si on lit ce fichier nouvellement créé en définissant le bon encodage (celui utilisé pour l'écriture), tout se passe bien :
>>> f2 = open('fichier_latin9.txt', 'r', encoding='latin9')
>>> contenu = f2.read()
>>> f2.close()>>> print(contenu)
Représentation d'un texte en machineMais si on le lit en définissant l'encodage UTF-8, il y a un problème :
>>> f2 = open('fichier_latin9.txt', 'r', encoding='utf-8')
>>> contenu = f2.read()
>>> f2.close()>>> print(contenu) # c'est le 'é' qui pose problème au décodage
---------------------------------------------------------------------------
UnicodeDecodeError Traceback (most recent call last)
<ipython-input-11-138de5bdad86> in <module>
1 f2 = open('fichier_latin9.txt', 'r', encoding='utf-8')
----> 2 contenu = f2.read()
3 print(contenu)
4 f2.close()
D:\Anaconda\lib\codecs.py in decode(self, input, final)
320 # decode input (taking the buffer into account)
321 data = self.buffer + input
--> 322 (result, consumed) = self._buffer_decode(data, self.errors, final)
323 # keep undecoded input until the next call
324 self.buffer = data[consumed:]
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe9 in position 4: invalid continuation byteEn vous aidant de ce qui vient d'être dit, écrivez un programme Python qui permet de convertir le fichier fichier_latin9.txt (encodé en Latin-9) créé juste au-dessus en un fichier fichier_converti.txt encodé en UTF-8.
Références
Germain Becker, Lycée Emmanuel Mounier, Angers.

Voir en ligne : info-mounier.fr/premiere_nsi/types_base/caracteres
{kind=link}
{kind=link}