On dispose de la grille $2 \times 3$ ci-dessous.
Question : Combien de chemins mènent du coin supérieur gauche au coin inférieur droit, en se déplaçant uniquement le long des traits horizontaux vers la droite et le long des traits verticaux vers le bas ? Et pour une grille $10 \times 10$ ?
Pour une grille de taile $2 \times 3$, il y a dix chemins. Sur la grille, on a ajouté ci-dessous le nombre de chemins pour arriver à chaque coin (en partant du coin supérieur gauche). Pour obtenir un de ces nombres, il suffit d'additionner les nombres situés à gauche et au-dessus.
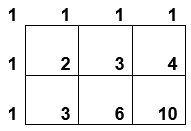
Pour une grille de taille $10 \times 10$, il y a 184756 chemins possibles...
Pour déterminer la réponse, on peut s'appuyer sur les résultats de calculs précédents, c'est la base de la programmation dynamique.
La programmation dynamique est une technique dûe à Richard Bellman dans les années 1950. À l'origine, cette méthode algorithmique était utilisée pour résoudre des problèmes d'optimisation. L'idée générale est de déterminer un résultat sur la base de calculs précédents.
Plus précisément, la programmation dynamique consiste à résoudre un problème en le décomposant en sous-problèmes, puis à résoudre les sous-problèmes, des plus petits au plus grands en stockant les résultats intermédiaires.
Le terme programmation désigne la planification, et n'a pas de rapport avec les langages de programmation.
Nous allons illustrer le principe de la programmation dynamique sur le calcul du $n$-ième terme de la suite de Fibonacci.
On a déjà abordé cette suite lorsque nous avons parlé de la programmation récursive (Thème 4, Chapitre 1). Mais voilà quelques rappels :
La suite de Fibonnacci est une suite de nombres dont chacun est la somme des deux précédents. Le premier et le second nombres sont égaux à 0 et 1 respectivement. On obtient la suite de nombres : 0 - 1 - 1 - 2 - 3 - 5 - 8 - 13 - 21 - ...
Mathématiquement, cette suite notée $(F_n)$ est donc définie par :
Vous avez déjà programmé une version récursive qui renvoie le terme de rang $n$ de cette suite.
def fibo(n):
"""Version récursive naïve"""
if n == 0 or n == 1: # ou n <= 1
return n
else:
return fibo(n-1) + fibo(n-2)Par exemple, voici l'arbre des appels récursifs si on lance fibo(5).
fibo(5)
/ \
fibo(4) fibo(3)
/ \ / \
fibo(3) fibo(2) fibo(2) fibo(1)
/ \ / \ / \
fibo(2) fibo(1) fibo(1) fibo(0) fibo(1) fibo(0)
/ \
fibo(1) fibo(0)On se rend compte qu'il y a beaucoup d'appels redondants : fibo(1) a été lancé 5 fois, fibo(2) a été lancé 3 fois, etc.
Ces redondances entraînent un nombre d'appels récursifs qui explose rapidement dès que $n$ est élevé. Par conséquent, les temps de calcul deviennent vite très élevés. Pire, dès que $n$ est trop grand, l'algorithme ne donnera jamais la réponse.
import time
def temps_fibo(n):
t0 = time.time()
resultat = fibo(n)
t1 = time.time()
print(f"{resultat} \nrésultat obtenu en {t1-t0} s.")>>> temps_fibo(5)
5
résultat obtenu en 0.0 s.>>> temps_fibo(30)
832040
résultat obtenu en 0.0 s.>>> temps_fibo(37)
24157817
résultat obtenu en 10.93546175956726 s.Il est possible de faire mieux, en évitant de refaire les calculs déjà effectués. Pour cela, il faut stocker les résultats intermédiaires !
Une première approche est d'adapter l'algorithme récursif en stockant les résultats calculés dans un tableau ou un dictionnaire. Lors d'un appel, on commence par vérifier si on ne connaît pas déjà la réponse, auquel cas on la renvoie directement, ce qui évite d'effectuer des calculs redondants.
On peut utiliser un tableau memo pour stocker les résultats au fur et à mesure. Dans chaque case i du tableau, on stockera la valeur $F_i$ dès qu'on l'aura calculée. Au départ, on peut initialiser toutes les cases du tableau à la valeur None, ce qui permettra de savoir si une valeur n'a pas encore été calculée. Cela donne la fonction suivante :
def fibo_memo(n, memo):
if memo[n] is not None: # si calcul déjà effectué
return memo[n] # on renvoie directement sa valeur
elif n == 0 or n == 1:
memo[n] = n
return n # ou memo[n]
else:
memo[n] = fibo_memo(n-1, memo) + fibo_memo(n-2, memo)
return memo[n]Explications :
n du tableau n'est pas None, c'est qu'on a déjà calculé $F_n$ et il suffit alors de renvoyer sa valeur memo[n]memo avant de la renvoyern, ce qui permet de la réutiliser directement dès qu'on en a besoin.Il n'y a plus qu'à lancer le premier appel avec un dictionnaire vide, c'est ce que fait la fonction fibo suivante.
def fibo(n):
"""Version récursive avec mémoïsation"""
memo = [None] * (n+1) # initialisation du tableau avec des None
return fibo_memo(n, memo)Le principe est exactement le même si memo est un dictionnaire pour stocker les résultats intermédiaires. En considérant que les clés sont les entiers i et leurs valeurs associées sont les $F_i$. Si la clé i n'est pas dans le dictionnaire, c'est qu'on n'a pas encore calculé $F_i$. On obtient une fonction quasiment similaire :
def fibo_memo(n, memo):
if n in memo: # si calcul déjà effectué
return memo[n] # on renvoie directement sa valeur
elif n == 0 or n == 1:
memo[n] = n
return n # ou memo[n]
else:
memo[n] = fibo_memo(n-1, memo) + fibo_memo(n-2, memo)
return memo[n]Explications : la valeur $F_n$ a déjà été calculée si n est une clé du dictionnaire memo, ce qu'on teste à la ligne 2. Le reste du code est inchangé mais gardez en tête que memo est dans ce cas un dictionnaire : en particulier, les lignes 5 et 8 créent un nouveau couple $(n, F_n)$ dans le dictionnaire memo.
def fibo(n):
"""Version récursive avec mémoïsation"""
memo = {} # initialisation avec un dictionnaire vide
return fibo_memo(n, memo)Si vous considérez que ce n'est pas pratique de passer en paramètre notre tableau ou notre dictionnaire memo à la fonction récursive, il est possible d'utiliser ce qu'on appelle une fonction englobante qui aura le rôle de notre fonction d'interface :
def fibo(n):
memo = [None] * (n+1)
def fibo_memo(n):
if memo[n] is not None: # si calcul déjà effectué
return memo[n] # on renvoie directement sa valeur
elif n == 0 or n == 1:
memo[n] = n
return memo[n]
else:
memo[n] = fibo_memo(n-1) + fibo_memo(n-2)
return memo[n]
return fibo_memo(n)Ici, fibo est la fonction englobante, à l'intérieur de laquelle on a définit notre fonction récursive mémoïsée. On voit alors que :
memo dans la fonction englobante fibo mais en dehors de fibo_memomemo est une variable partagée en mémoire (une liste Python) la fonction fibo_memo peut l'utiliser sans avoir besoin qu'on la passe en paramètre, ce qui permet d'obtenir des écritures plus simples et identiques à la version récursive sans mémoïsationNotez que dans ce cas, que ni le tableau memo ni la fonction fibo_memo n'existent en dehors de la fonction englobante, ce qui n'est pas du tout un problème car ils n'ont pas d'intérêt à être utilisés en dehors de la fonction fibo.
On peut bien sûr écrire une version similaire dans le cas où memo est un dictionnaire :
def fibo(n):
memo = {}
def fibo_memo(n):
if n in memo: # si calcul déjà effectué
return memo[n] # on renvoie directement sa valeur
elif n == 0 or n == 1:
memo[n] = n
return memo[n]
else:
memo[n] = fibo_memo(n-1) + fibo_memo(n-2)
return memo[n]
return fibo_memo(n)Avec ce procédé de mémoïsation, l'arbre des appels est considérablement réduit puisqu'il n'y a plus aucun appel redondant. Par exemple, l'arbre des appels récursifs en lançant fibo(5) se réduit à :
fibo(5)
/ \
fibo(4) fibo(3)
/ \
fibo(3) fibo(2)
/ \
fibo(2) fibo(1)
/ \
fibo(1) fibo(0)On constate alors qu'avec cette version, les valeurs $F_n$ sont calculées quasiment instantanément et que l'on peut obtenir les valeurs $F_n$ pour des grandes valeurs de $n$.
>>> temps_fibo(5) # version récursive avec mémoïsation
5
résultat obtenu en 0.0 s.>>> temps_fibo(30)
832040
résultat obtenu en 0.0 s.>>> temps_fibo(37)
24157817
résultat obtenu en 0.0 s.>>> temps_fibo(850)
1949885951587339044875793733356219760673772926586260591210358470405525665390243100575540781157408285819450131557173898143210104351541330710230926558457389046268596497514105167175
résultat obtenu en 0.001992464065551758 s.La version récursive avec mémoïsation correspond à une approche descendante, aussi appelée haut-bas (ou top-down en anglais). En effet, pour connaître $F_n$ on lance l'appel fibo(n) qui déclenche la descente d'appels récursifs jusqu'aux cas de base pour lesquels on mémorise les résultats. Dans un second temps, on remonte les appels tout en mémorisant leurs résultats pour ne pas résoudre plusieurs fois le même problème.
Finalement, avec cette méthode, c'est lors de la remontée des appels que leurs résultats sont mémorisés puis réutilisés sur les problèmes plus grands. On peut alors se demander si on ne peut pas procéder directement du plus petit sous-problème au plus grand (celui que l'on veut résoudre). La réponse est oui ! Et on explique cela de suite.
On parle aussi de méthode bas-haut, ou bottom-up en anglais.
Une autre manière de résoudre le problème est d'utiliser une approche ascendante.
Il s'agit d'une méthode itérative dans laquelle on commence par calculer des solutions pour les sous-problèmes les plus petis puis, de proche en proche, on arrivera à la taille voulue. Comme précédemment, on utilise le principe de la mémoïsation pour stocker les résultats partiels.
Le calcul du terme $F_n$ de la suite de la Fibonacci n'est pas un problème d'optimisation, ainsi le calcul d'une solution d'un problème à partir des solutions connues des sous-problèmes est simple puisqu'il n'y a aucun choix à faire.
De manière générale, on utilise un tableau pour stocker les résultats au fur et à mesure. Voici les étapes habituelles :
F de taille $n+1$ qui va contenir les valeurs $F_0$, $F_1$, ..., $F_n$ dans cet ordreF avec $n+1$ zéros initialementUtilisation de la formule de récurrence pour remplir le reste du tableau :
F en parcourant les indices par ordre croissant : on va mettre dans F[i] la valeur F[i-1] + F[i-2] que l'on connaît puisque ces deux valeurs ont été calculés précédemment.Cela donne la fonction suivante.
def fibo(n):
"""Version itérative ascendante"""
F = [0] * (n+1)
F[0] = 0 # pas indispensable car déjà initialisé à 0
F[1] = 1
for i in range(2, n + 1):
F[i] = F[i-1] + F[i-2]
return F[n]Les performances sont semblables à la version récursive avec mémoïsation :
>>> temps_fibo(850) # version itérative ascendante
1949885951587339044875793733356219760673772926586260591210358470405525665390243100575540781157408285819450131557173898143210104351541330710230926558457389046268596497514105167175
résultat obtenu en 0.0 s.Il existe de nombreux problèmes pouvant être résolus avec le paradigme de la programmation dynamique, dont beaucoup de problèmes d'optimisation :
✏️ Passez aux exercices !
Le programme officiel cite les exemples du rendu de monnaie et de l'alignement de séquences comme des exemples pouvant être présentés. Il sont détaillés en exercices mais voici tout de même un résumé condensé qui pourra servir de révisions.

Crédits : Image par Memed_Nurrohmad de Pixabay
On a vu en Première que l'on peut résoudre ce problème avec un algorithme glouton mais que ce dernier ne fournit pas nécessairement une solution optimale (et parfois fausse selon le système monétaire utilisé).
Une autre approche est d'utiliser la force brute en testant toutes les combinaisons possibles. On peut le faire de manière récursive mais le nombre de combinaisons à tester devient vite trop important pour que cette solution soit satisfaisante.
On peut chercher à exprimer le problème (rendre une somme $s$) à partir de sous-problèmes plus petits (rendre une somme plus petite que $s$). On aboutit à la relation de récurrence suivante sur le nombre de pièces optimal pour rendre une somme $s$ :
En effet, l'idée est la suivante : pour rendre la somme $s$ de façon optimale il faut rendre une pièce $p$ et la somme $s-p$ de façon optimale. Pour cela, il faut tester toutes les pièces $p$ possibles et prendre celle qui minimise le nombre de pièces pour rendre pour la somme $s-p$ (d'où la recherche du minimum)
L'algorithme récursif classique a une efficacité catastrophique car le nombre d'appels explose à cause des nombreuses redondances. On peut améliorer cette version récursive en utilisant la programmation dynamique : pour cela on stocke les résultats connus dans un tableau memo et on renvoie directement les résultats connus pour éviter les appels récursifs redondants.
def rendu_recursif_memoise(pieces, somme):
"""Version récursive avec mémoïsation"""
memo = [None] * (somme + 1) # intialisation du tableau avec des None
return rendu_recursif_memo(pieces, somme, memo)
def rendu_recursif_memo(pieces, somme, memo):
if memo[somme] is not None: # si calcul déjà effectué
return memo[somme] # on le renvoie directement
elif somme == 0:
memo[somme] = 0
return 0
else:
nb_pieces = somme # nb_pieces = 1 + 1 + ... + 1 dans le pire des cas
for p in pieces:
if p <= somme: # inutile de tester les pièces de valeur > somme
nb_pieces = min(nb_pieces, 1 + rendu_recursif_memo(pieces, somme - p, memo))
memo[somme] = nb_pieces
return nb_pieces>>> rendu_recursif_memoise([1, 2], 100)
50On procède classiquement :
nb de taille $somme + 1$ qui va permettre de stocker les valeurs $\text{nb_pieces}(0)$, $\text{nb_pieces}(1)$, ..., $\text{nb_pieces}(\text{somme})$ dans cet ordre.nb avec $somme + 1$ zéros initialementnb[0] est alors déjà correctement initialiséenb en parcourant les indices par ordre croissant (on fait varier s de 1 à somme) en utilisant la formule de récurrenceCela donne la fonction suivante :
def rendu_iteratif_ascendant(pieces, somme):
"""Version itérative ascendante"""
# ÉTAPE 1 : création et initialisation du tableau
nb = [0] * (somme+1) # nb[0] est ainsi bien initialisé
# ÉTAPE 2 : remplissage du reste du tableau par indice croissant
for s in range(1, somme + 1):
nb[s] = s # nb[s] = 1 + 1 + ... + 1 dans le pire des cas
for p in pieces:
if p <= s:
nb[s] = min(nb[s], 1 + nb[s-p])
# ÉTAPE 3 : le résultat est dans la dernière case
return nb[s]>>> rendu_iteratif_ascendant([1,2], 100)
50En remplaçant l'étape 1 par
nb = {0: 0}on obtient une version qui mémorise les résultats intermédiaires dans un dictionnaire
nbà la place du tableau (il se trouve que le reste est inchangé même s'il faut garder en tête que l'on manipule un dictionnaire).
Le problème de l'alignement de séquences est très utilisé en bio-informatique pour trouver des correspondances dans des séquences d'ADN.

Crédits : Fdardel, CC BY-SA 3.0, via Wikimedia Commons
Décontextualisation : On peut représenter deux séquences comme deux chaînes de caractères $T_1$ et $T_2$ et l'objectif est d'étudier leur degré de similarité (ou dissimilarité). Pour cela on peut chercher à minimiser la distance $d(T_1, T_2)$ entre les deux chaînes.
Pour passer d'une chaîne à l'autre on dispose de 3 opérations, chacune ayant un coût égal à 1 :
On appelle distance d'édition, notée $\text{dE}$, le nombre minimal de caractères qu'il faut insérer, supprimer, ou substituer pour passer d'une chaîne à l'autre, c'est-à-dire celle qui minimise le coût des alignements possibles. La distance d'édition permet donc d'obtenir un aligment optimal.
Exemple : Un alignement optimal des chaînes SUCCES et ECHECS est
S U C C E - S
- E C H E C Sdont le coût est égal à 4, donc $\text{dE(SUCCES, ECHECS) = 4}$
On peut dégager une relation de récurrence car le calcul de la distance d'édition entre deux chaînes peut se faire à partir de celles de chaînes plus petites.
On a la relation suivante :
En effet, pour aligner de manière optimale $T_1[1..i]$ et $T_2[1..j]$, il y a trois cas de figure (quatre en fait) :
La version récursive naïve permettant de calculer la distance d'édition a un coût en temps catastrophique car les appels sont redondants. On peut améliorer cela à l'aide de la technique de mémoïsation comme pour les autres exemples mais on ne présente dans la suite que la version itérative ascendante.
On note $n_1$ et $n_2$ les longueurs respectives de $T_1$ et $T_2$.
On procède classiquement :
d à deux dimensions de taille $(n1 + 1)\times(n2 + 1)$ qui va permettre de stocker en position $(i, j)$ la distance d'édition entre les $i$ premiers caractères de $T_1$ et les $j$ premiers caractères $T_2$ (d[i][j] $= \text{dE}(T_1[1..i], T_2[1..j])$).d avec uniquement des zéros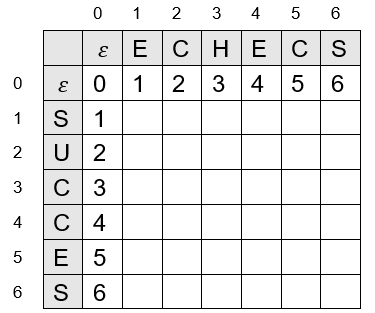
Utilisation de la formule de récurrence pour remplir le reste du tableau :
d avec deux boucles imbriquées qui parcourent les indices par ordre croissant (on fait varier $i$ de $1$ à $n_1$ et $j$ de $1$ à $n_2$ ) en utilisant la formule de récurrence.Cela donne la fonction suivante.
def dE(t1, t2):
"""Version itérative ascendante"""
# ÉTAPE 1 : création et initialisation du tableau
n1 = len(t1)
n2 = len(t2)
d = [[0] * (n2 + 1) for i in range(n1 + 1)]
for i in range(n1 + 1): # remplissage première colonne
d[i][0] = i
for j in range(n2 + 1): # remplissage première ligne
d[0][j] = j
# ÉTAPE 2 : remplissage du reste du tableau par indice croissant
for i in range(1, n1 + 1):
for j in range(1, n2 + 1):
if t1[i-1] == t2[j-1]: # le k-ième caractère est en position k-1
cout_sub = 0 # correspondance
else:
cout_sub = 1 # substitution
d[i][j] = min(d[i-1][j] + 1, d[i][j-1] + 1, d[i-1][j-1] + cout_sub)
# ÉTAPE 3 : le résultat est dans la dernière case
return d[n1][n2], d # on renvoie aussi le tableau d pour l'observer>>> dE('SUCCES', 'ECHECS')
(4,
[[0, 1, 2, 3, 4, 5, 6],
[1, 1, 2, 3, 4, 5, 5],
[2, 2, 2, 3, 4, 5, 6],
[3, 3, 2, 3, 4, 4, 5],
[4, 4, 3, 3, 4, 4, 5],
[5, 4, 4, 4, 3, 4, 5],
[6, 5, 5, 5, 4, 4, 4]])Contrairement à la version récursive naïve, on peut obtenir les distances entre deux chaînes assez longues.
>>> dE('ALGORITHME', 'ALGORIHTME')
(2,
[[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
[1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9],
[2, 1, 0, 1, 2, 3, 4, 5, 6, 7, 8],
[3, 2, 1, 0, 1, 2, 3, 4, 5, 6, 7],
[4, 3, 2, 1, 0, 1, 2, 3, 4, 5, 6],
[5, 4, 3, 2, 1, 0, 1, 2, 3, 4, 5],
[6, 5, 4, 3, 2, 1, 0, 1, 2, 3, 4],
[7, 6, 5, 4, 3, 2, 1, 1, 1, 2, 3],
[8, 7, 6, 5, 4, 3, 2, 1, 2, 2, 3],
[9, 8, 7, 6, 5, 4, 3, 2, 2, 2, 3],
[10, 9, 8, 7, 6, 5, 4, 3, 3, 3, 2]])Pour trouver un alignement optimal entre $T_1$ et $T_2$ il suffit de remonter depuis d[n1][n2] vers d[0][0] (de la case en bas à droite à celle en haut à gauche) en considérant à chaque fois le "meilleur" des 3 voisins, c'est-à-dire celui par lequel on a pu arriver ! (il peut parfois y en avoir plusieurs).
Par exemple, le tableau d correspondant à l'alignement entre SUCCES et ECHECS est :
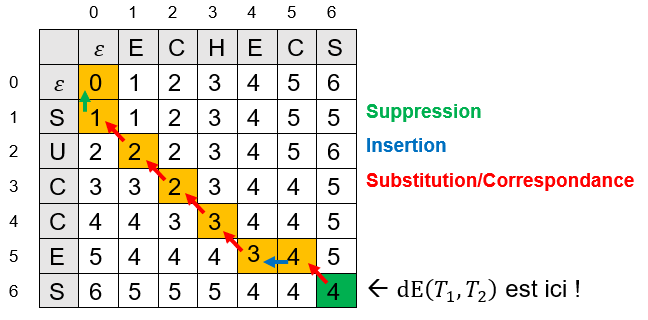
On peut alors construire un alignement optimal (en partant de la fin ou du début) :
S U C C E - S
- E C H E C SRéférences :
Germain BECKER, Lycée Mounier, ANGERS
Ressource éducative libre distribuée sous Licence Creative Commons Attribution - Partage dans les Mêmes Conditions 4.0 International

Voir en ligne : info-mounier.fr/terminale_nsi/algorithmique/programmation-dynamique
{kind=link}